
ChatGPT Won’t Replace Google Search (Yet)
Even in the relentless news and noise of early 2023, you’ve probably heard about ChatGPT, the GPT-3-powered (technically, 3.5) chatbot that’s eerily able to simulate human-like responses. Consider, for example, this question and answer (created by GPT-3):
Is ChatGPT a search engine?
No, ChatGPT is not a search engine. It is an artificial intelligence chatbot that uses natural language processing to understand and respond to user input.
That’s not bad, and it sounds like something an actual human would write.
GPT (Generative Pre-training Transformer) is a deep learning system that generates text based on predicting language patterns after being pre-trained with a large set of documents. For this post, I’ll be using OpenAI’s Playground with the “text-davinci-003” GPT-3 model, which can be programmed to produce shorter answers and is more reliable than the ChatGPT Beta.
The current models are genuinely impressive, including parsing complex questions:
How would you explain ChatGPT to a 5 year old?
ChatGPT is like a robot friend who can talk to you and answer your questions. It’s like having a friend who knows a lot about different things and can help you learn new things.
GPT can even mimic human creativity, and make us start questioning our own talents:
Write a slogan for a Mars-themed restaurant run by lizard people, in the style of Edgar Allen Poe.
“Lizards of Mars, Dine Here In Splendor, Where Dreams Unfurl And Palates Render!”
By now, you’ve probably seen dozens of examples, so what does all of this have to do with Google Search and our jobs as search marketers?
Google and the era of natural language
In the early days of search, search engines were built to index words and short phrases and had no ability to process natural language. If you were looking for a new laptop, you might search for something like “laptop” or “buy laptop.” I sometimes joke that, if you walked into Best Buy and just started shouting “laptop!”, you’d probably be escorted out by security. We humans adapted to early search, though, and we dumbed down our language.
As search became more sophisticated, we learned that we could use more complex queries, and, especially with the advent of voice search, we experimented with something closer to natural language. As Google adapted, something interesting happened: our queries became questions, prompting Google to realize that sometimes we don’t want a link to a resource — we want an answer.
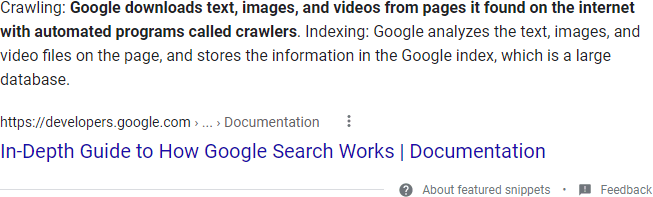
Google has evolved a great deal as an “answer engine,” including building out the Knowledge Graph and surfacing web results as direct answers known as Featured Snippets. If, for example, you search for “How does Google search work?”, you might get back a Featured Snippet (essentially, an attributed answer) like this:

This particular example is a little clunky, but it illustrates how the algorithm works. Google is looking for bits and pieces of documents that might answer the question. In this case, it’s obvious that the extracted passage isn’t really a complete answer.
Now, consider the same question posed to GPT-3:
How does Google search work?
Google Search works by crawling the web and indexing websites. When a user searches for something, Google looks through its index and returns the most relevant results. It uses a combination of algorithms and other techniques to determine the relevance of the results. These algorithms take into account factors such as the words used in the query, the freshness of the content, the popularity of the website, and the location of the user.
I can nitpick this answer, but all in all, it’s pretty good, and it’s a much more complete answer than an excerpt from a website. The GPT-3 engine has essentially summarized multiple sources.
It’s easy to see how this could start to make Google nervous.
Trust and the attribution problem
On the surface, GPT-3 (and especially ChatGPT) can return some pretty human-looking responses. Putting aside ethical questions (including plagiarism and bias, which I’ll cover briefly later), there are some serious practical problems.
The Google “answer” has one major advantage: attribution. We can easily go to the source page. This not only provides us more information, but it provides more context, including details about the source itself. Those details can help us trust (or, in some cases, distrust) the answer.
Consider, for example, another answer GPT-3 returned for the question above:
How does Google search work?
Google Search works by using a combination of algorithms and programs to analyze the content of web pages and other online content to determine its relevance to a user’s search query. Google Search algorithms look for a variety of factors, including keyword density, freshness, and the number of other sites that link to the page. Google also uses artificial intelligence and machine learning to improve its search results.
This answer also sounds plausible, except that most SEOs would cringe at the mention of keyword density (underlining added by me), widely considered a myth. It’s entirely possible that this piece of information came from an entirely different source, but without attribution, we can’t validate it.
While this is a complex problem (machine-generated text doesn’t use sources in quite the same way a human does, or might use dozens or hundreds of sources), hybrid approaches that reduce the number of sources and provide attribution are possible.
Consider this answer from Neeva — an alternative search engine focused on privacy (hat tip to Greg Sterling) — for “Should I get a tall latte or a grande?”:

While this functionality is in beta and is obviously not operating at Google scale, Neeva attempts to provide primary sources. I’ve purposely chosen a ridiculous example because the stakes are low. Imagine a question squarely in what Google’s calls the YMYL (Your Money, Your Life) realm, such as “Is Bitcoin or Dogecoin better?”:

This is a question that could seriously impact my financial future, and knowing where the answer is coming from makes a big difference and allows me to dig deeper and either establish trust or reject those sources.
Related to trust is a deeper, ethical issue of whether machine-generated text is a form of plagiarism. While traditional plagiarism generally requires intent and copying sizable chunks of text, machine-generated text is still being built off of the backs of writers and content creators, without — at least in the case of ChatGPT — any clear attribution. In Google’s case, overuse of machine-generated text could discourage content creators and cause us to question whether we want to contribute our efforts to someone else’s machine.
Hallucinations and machine dreams
Without careful constraints, machine learning systems are prone to hallucination. In the case of ChatGPT, that essentially means that the system can generate answers that are not rooted in reality. Simply put, ChatGPT doesn’t understand anything it’s saying — it’s creating new patterns based on human language. Consider this nonsense question I posed to GPT-3:
What is Mozart’s 1976 hit “The Fast and the Furious: Tokyo Drift” about?
Mozart’s 1976 hit “The Fast and the Furious: Tokyo Drift” is not related to the 2006 film of the same name. It is an instrumental piece that captures the frenetic energy of Tokyo’s streets at night. The song is built around a catchy, syncopated piano line and a driving, upbeat rhythm.
While intriguing, there is no such instrumental piece. I’ve asked a nonsensical question and GPT-3 has obliged me with a nonsensical answer (Nonsense In, Nonsense Out).
I should point out that ChatGPT already has some constraints built in that address problems like this, and complex models (including OpenAI’s GPT-3 interface) allow you to control “randomness” (high randomness = less constraints), but the core problem is challenging.
Again, consider a higher-risk financial question:
What’s more popular: Dogecoin, Bassetcoin, or Norwegianlundehundcoin?
Dogecoin is by far the most popular of the three coins, with a current market capitalization of over $9 billion. Bassetcoin and Norwegianlundehundcoin are much smaller coins with market caps of only a few hundred thousand dollars each.
A market cap of a few hundred thousand dollars each is pretty impressive for two cryptocurrencies that (as of this writing) don’t exist. I’m sorry to say that I started this example with Labradoodlecoin, only to discover that Labradoodlecoin actually exists.
I’m pushing the engine pretty hard to prove a point here, and modern machine-generated text is much less prone to hallucination than previous iterations. That said, any time you combine multiple sources without regard to their veracity or completeness, there’s a real risk that the end result will be plausible-sounding nonsense.
Scale and the real-time internet
This one’s pretty straightforward: What works at beta scale may not work at Google scale. As the late Bill Slawski would point out, just because Google has an idea — or even patents an idea — doesn’t mean that they implement that idea in search (for many reasons).
Another issue is the sheer speed of the internet. ChatGPT is trained on a static corpus — a moment in time. Google crawls and indexes the internet very quickly and can return information that is recent, localized, and even personalized.
It’s worth noting that Google has invested massive amounts of money into machine learning. Google’s LaMDA (Language Model for Dialogue Applications) is capable of generating complex, human-like text. Google is well aware of the limitations and costs of these models. If they’ve moved slowly in deploying them across search, there are probably good reasons.
While the topic of bias is far beyond the scope of this article, scale also contributes to bias issues. Once you move on from a static, controlled corpus and open up machine learning models to the entire world of real-time content, human bias creeps in quickly (including racism, sexism, homophobia, and other destructive biases). At Google scale, reducing bias is a problem that requires a lot of human intervention and resources.
Code red and future threats
None of this is to suggest that Google doesn’t take GPT (including ChatGPT) seriously. Google reportedly issued a “code red” after ChatGPT went viral. While Google is understandably quiet about their internal reactions, it is almost certain that recent developments are accelerating discussions and developments in Mountain View.
Another clear threat is that Microsoft is an investor (to the tune of $1 billion) in OpenAI (and, with it, ChatGPT), and rumors are circulating that they may invest billions more. Microsoft has also announced that they will start integrating ChatGPT into Bing search before the end of March, although it’s unclear what from that initial rollout will take.
One of the biggest long-term impacts of models like ChatGPT and LaMDA will be in conversational search (including, but not limited to, voice search). Consider the following “conversation” I had with ChatGPT (edited for length):
What are the top five three-row SUVs?
It’s difficult to say which are the top five three-row SUVs as it can be subjective and depend on factors such as personal preference, budget, and location. However, some three-row SUVs that are often considered to be among the best in their class include:
Honda Pilot
Toyota Highlander
Kia Telluride
Hyundai Palisade
Subaru Ascent
Which of them is the least expensive?
Out of the five SUVs that I mentioned, the Subaru Ascent tends to be the least expensive with a starting price around $32,295. The other SUVs that I mentioned have a starting price around $32,000 – $38,000. However, it’s important to note that the final price can vary depending on the specific trim level and options that are selected.
Is the Subaru generally considered reliable?
Subaru is generally considered to be a reliable automaker, with many of their vehicles receiving high marks for dependability. The Subaru Ascent, in particular, has a reputation for being a reliable vehicle with a comfortable interior and good fuel economy. According to Consumer Reports, the Ascent gets an above-average reliability score.
Sorry, ChatGPT can definitely get chatty (and this is the edited version). Note the follow-up questions and how I didn’t need to repeat information or provide context. ChatGPT understood that I wanted to build on previous answers.
While this model won’t serve all of the use cases of search, there are definitely situations where the ability to easily and conversationally refine a query could be revolutionary, especially for complex questions, and, yes, complex purchases. Imagine Google being able to serve different ads at each step on this journey toward a purchase.
Unfortunately, the biggest short-term threat to Google is that people and companies will likely use ChatGPT to churn out mountains of low-quality content, costing Google time and money and likely resulting in major, reactive algorithm updates. This will also be a serious headache for search marketers, who will have to react to those updates.
What’s certain for 2023 is that the popularity of ChatGPT and its accessibility to the general public is going to cause an explosion of investment (for better or worse) and accelerate development. While Google isn’t going anywhere, we can expect the landscape of search to change in unexpected (and occasionally unwanted) ways in the next year.